This project has been in the works for a couple weeks, dare I say years because it's something I've always wanted to build. I built a few prototypes trying out different technologies over the last couple months and ran into issues each time. So I've just been iterating and fixing and learning new things while trying to define a viable scope for version 1.
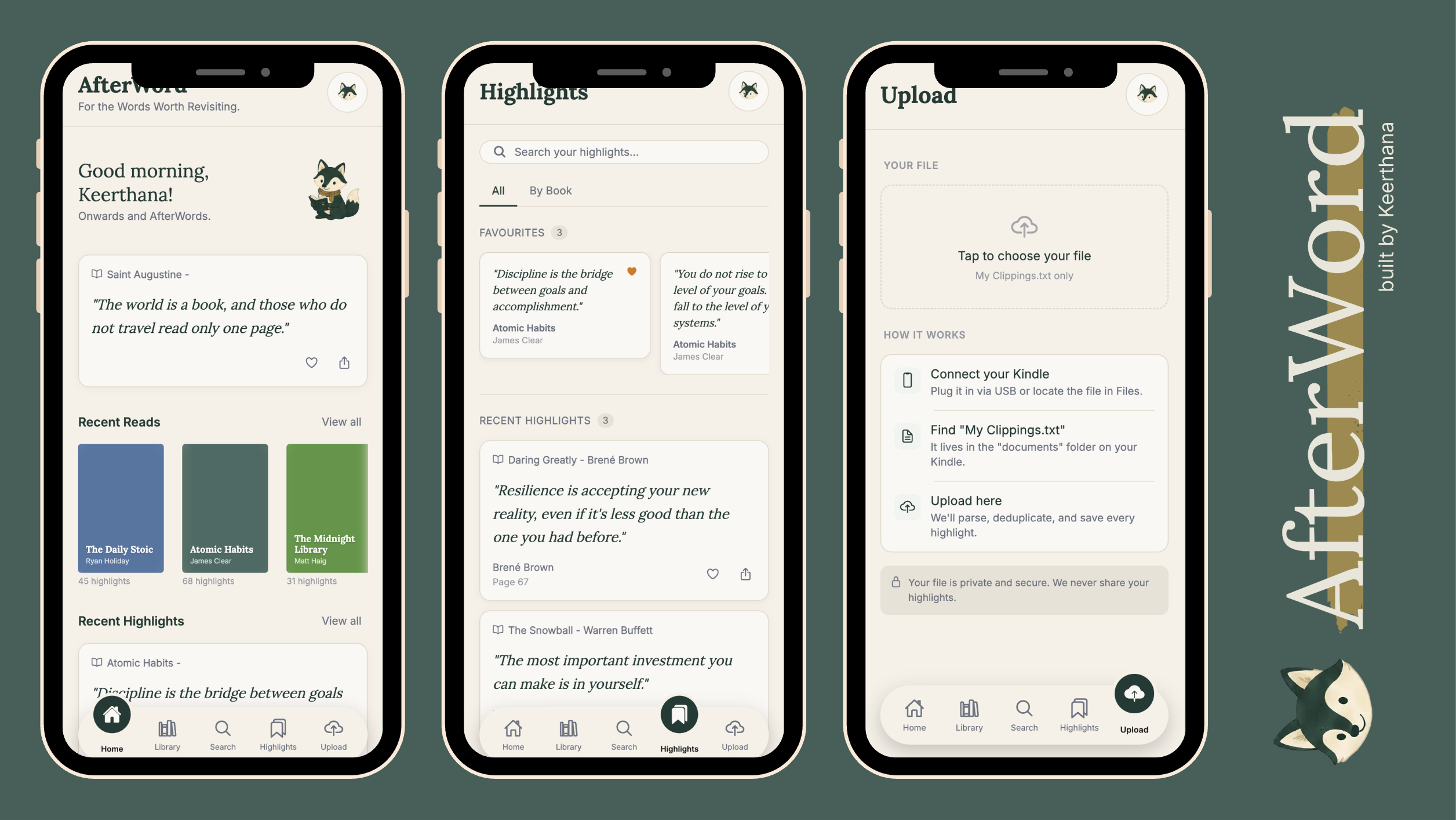
The core idea was that it should parse my kindle highlights and make them easy to view and search through. Also resurface highlights everyday so I can remember what I read in a more meaningful way. Readwise already does this and more but the monthly price tag is insane.
Issue 1
I started out with a simple parser file and Postgresql database that takes in a kindle clippings.txt file and inserts this data into books and highlights tables. I was also able to implement a simple semantic search with pg-vector and sentence-transformers to actually pull up relevant highlights through concept and not just word matching. It was really cool to see all that actually work.
The problem now became that for a large clippings.txt file, which usually they are, I would time out on my processing and it's just not a good way to handle even an async job. My solution is to use job_queues and chunks instead.
The upload flow used to be:
User uploads My Clippings.txt
|
Parsing Logic + Storage
|
▼
Tables: books, highlights (queryable)
│
│ Direct invocation from frontend
▼
Search Function
· Embeds query string
· Runs pgvector cosine similarity search via RPC
· Returns ranked highlights with book metadata
Now it is:
[Frontend App] ──(Upload File)──> [Supabase Storage]
│
(Storage HTTP Webhook Trigger)
▼
[process-highlights function]
│
(Parses & Generates Chunks)
│
▼
[ingestion_chunks Queue Table]
▲
│
(Batched RPC Worker Invocation)
│
[process-chunks-worker function]
│
▼
(Generates Vectors)
[Supabase AI: gte-small]
Issue 2
Another thing I had to consider with this initial architecture was that having a books table and highlights table for each user could really throw off my rate limits for fetching book cover urls or other book information. For most of the book apps I've built I've used the OpenBooks API which is quite reliable but for this app, this free API will not scale very well.
So I'm refining my schema to have a global books database instead. The tradeoff is that this will mean n amount of joins with the user and the new global_books table for every book every user adds. BUT this amount will be less than the number of times I will have to fetch and cache each user.book info instead of just global_book info.
I hope that made sense? I'm literally just typing this out as I think through it.
Final Thoughts for Week 1
So getting the database schema and my backend systems ready to handle a little bit of scale is what I'm focusing on this week. I already have a Frontend prototype I built, with supabase auth and some basic pages set up which will be on the back burner for now until my parsing logic is complete.
I also have my Functional Requirements Doc that I'm constantly editing for scope and also my current Technical Design Doc which I hope does not change too much more so that I don't have to start over for the 3rd time with a new schema :sob:
Tasks I'm working on for this week are:
- Full Schema Migration
- Storage Bucket + Upload Policies setup with RLS
- Ingestion Pipeline Working
What's Next
Next week I'll be working on:
- Upload flow wireframes, empty state designs + connect to my backend functions
- Connect Library and Search UI pages to backend clients
If you have experience publishing an app on the PlayStore or the App Store, I would really love to hear your insights and tips on what you wish you knew. Setting up analytics for retention, designing onboarding flows, branding assets, etc is all also new to me so I would appreciate any advice on that front as well if, you, the one person reading this post also happens to have experience with this. Please and thank you, but mostly pls.
If you're interested in following along with the building of this app then please send me an email! I'll setup a waitlist if there's enough interest!